Why text analytics?
It helps in extraction of words. It improved in 1980s. Converting natural language into insight is called Text Analytics. Text is nothing but language present in natural language processing.

What are the possible sources of text?
How to generate value from the text data? Which data you want to use? What all sources give us textual information? Transaction, textual we get from data bases. What are the sources of text data? We can get textual data from social media like Facebook, Instagram, Twitter etc. Many text mining modules are running on social media. Emails, customer feedback, social media. Server and logs are not text data, they are semi-structured data. Things like news, blogs, reviews, advertisement and marketing data, customers opinion, polls, resume. All of these become the major source of the text data.
Text module reads the text and analysis which person is most appropriate for the role. What people search on google is also text data.
Understanding which research paper is most appropriate for your problems.
Classifying which tweet is negative, which is positive and which is neutral.
Use case of text analytics: Sentimental analytics
What are the challenges to analyse text data?
A well 1. 2. 3. 4. 5. structured file can be classified but the same is not for text file. Connect finding
Dialects within the same language
Unstructured Data
Patterns and keyword finding Volume and variety
Steps involved:
Unstructured Data: If there’s a folder and 20000 text files. Each of these create images of different size. You need to create a table with 20000 rows. We try to read all these files in separate rows. The file can be of pdf format with images.
Additional data cleaning steps
For example through Microsoft app, there’s a table on newspaper. You click the photo and that photo is automatically converted to an excel sheet. Moving off common words or STOP words.
- Proper case translation ‘BIG’ and ‘big’ are two different words for the machine.
- Removal of special characters like @ %$ etc.
- Removal of extra space or white-space.
- Removal of emoji and emoticons. If there is an icon it’s an emoji. If you type it by the
- keyboard it is emoticon.
- Mapping of common words into one. We call this process as stemming our
- lemmatisation. When different words mean same thing like run, ran and running. f. Stem means root. Stemming removes the prefix or suffix.
- Spelling mistake improving
- Removal of slang.
Machine learning modules cannot understand text directly, they understand numbers:
- Count vectorisation
- N grams
- Tf-IDF (Term frequency- inverses document’s q)
- Cosine similarity
- Word embeddings
7. Text mining projects they have very high dimensionality.
8. Regular classification models to do ML or segmentation.
Steps involved:
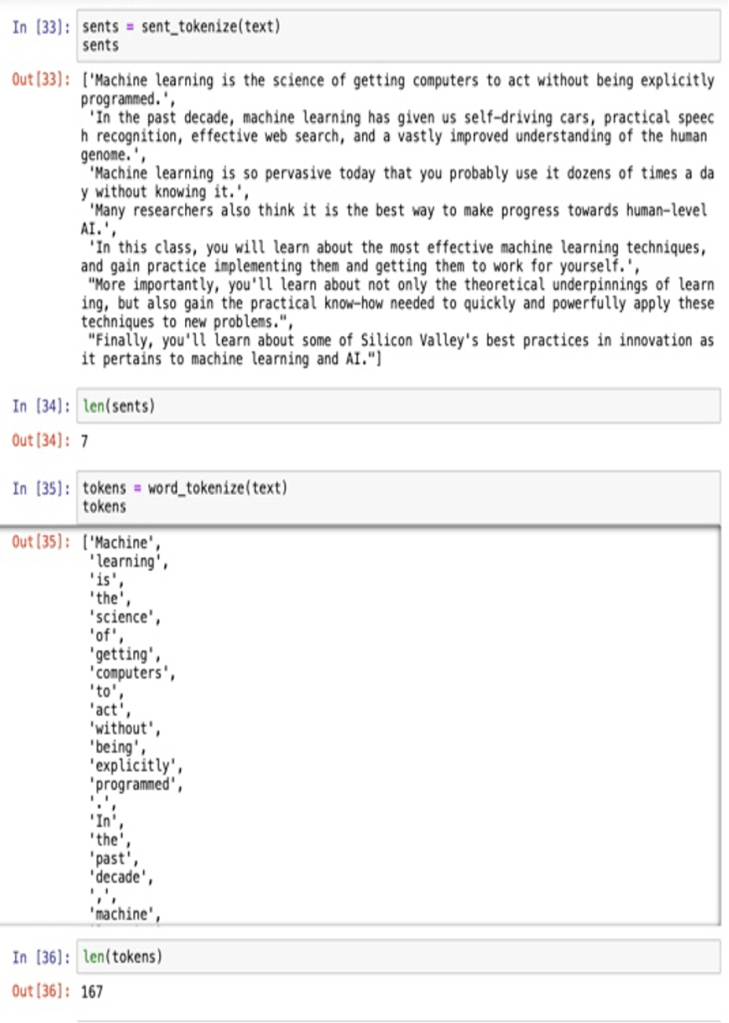
1. How to read a simple file in python.
2. How to read multiple text files as a pandas data frame in python
3. Image is not a text. We need a module that converts image into text. This method is called OCR
or optical character retention. We need an open source module which converts image into text.
How to remove certain data from text?
Suppose we extract data from twitter and we want to know which phone it was posted by iPhone or android? So we remove the URL.
Agenda:
1. How to read a simple file in python.
2. How to read multiple text files as a pandas data frame in python
3. Pull life Data from Twitter
4. A number of regular expressions- key for text projects
Image won’t be read and it will be lost. Each document is read in on Exide.
import os helps locates all the files or helps switch to a folder.
With open [‘MyTextFile.txt’,’r’] as f Go to the file with reader mode and pointer f. For line in f: read till the end
Print(line) #Print all of it
Loc folder location
Os.chdir(loc) changing working directory
Filelist= os.listdir() give list of all the files present in the working directory
Take a look at feature engineering on here we will specifically take a look at text data.
Representation in machine learning algorithms
High dimensionality reduction.
Which means inverse document frequency matrix, unigram, bigram, trigram similarity in the context of the text. Text data has wide application In the field of deep learning and artificial intelligence for example text data. Increasingly important to review brand perceptions. Some of the most common applications include:
- Analysing Amazon reviews
- Analysing tweets
- Analysing Facebook post
- And even YouTube reviews
- Books
It also has applications beyond social media to name of a few, we may give feedback in a restaurant or a saloon and that data needs to be analysed or chat data on the company‘s website. What type of questions do people ask on chat, most frequently asked questions , can be addressed and therefore making the process more efficient and user-friendly. Therefore, improving customer experience.
It gives a business insights into how customers perceive their overall sentiment about the brand and what features they like, what they dislike about a particular brand. When a new product launch, was it successful? If a brand is not making business in the market what is the customer perception been about the brand? Are there inside customer reviews to improve any features that can put the brand back into the business to expand the business further?
Can also be used to analyse competitor behaviour what are the features that customer like about a competitor brands for example analysing text is extremely powerful and growing in popularity.
How is text data represented for building machine learning solutions? Let’s take an example of these three sentences:
this is sentence 1
this is sentence 2
and this is sentence 3
To represent it we will think of each sentence as one document and the set of all the three sentences as a corpus.
Then we will create a vector representing account to words each document something like this:
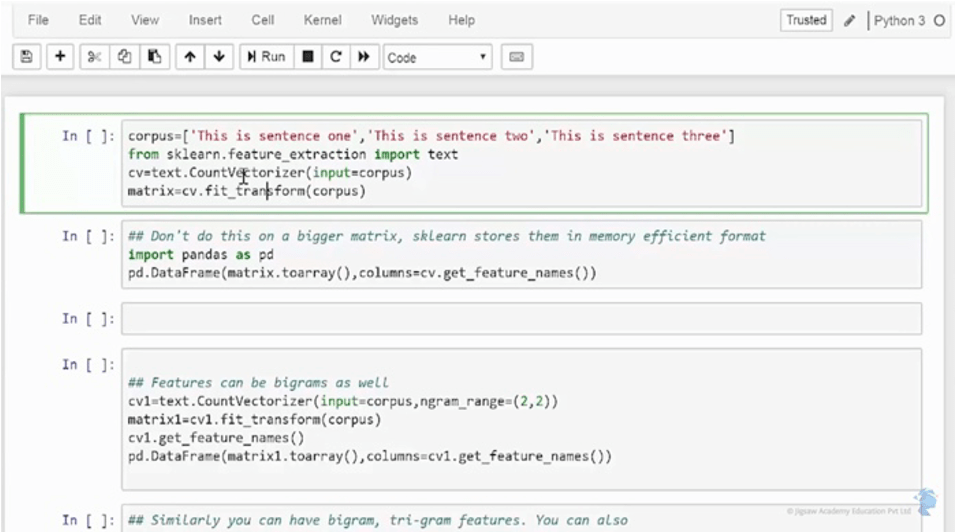

Created a vector of account of times each word occurs so the vector 111100 represents the count of words this is sentence 123 in document one.
This is also known as count matrix. Let’s first create a corpus consisting the documents. Here each document is separated by a ‘,’ as it’s a list and we will see this in a list called corpus which will be the input to build account vector matrix. To do this in Python we will use the package:
Sklearn.feature_extraction module
And within feature_extraction module we will import the textmodule.
We can then apply the count vectoriser function from the text module on the corpus.
It can be applied using the standard fit and transfer methods of this package sklearn.
I am applying the rule cv that we have built using the feet_transform to the corpus. Let’s save this in the object matrix. It is just for the sake of understanding how the CountVectorizer has been applied on the corpus.
Converting this into a data frame. Note, That this is not a regular practice because package
sklearn stores the matrix into a memory efficient format. It is this matrix that we will further use for machine learning algorithms.
Now just for the understanding has been applied on the corpus.
I’m converting this into a data frame. Note that this is not a regular practice because package sklearn stores the matrix into a memory efficient format.
It is this matrix we will further use for Machine Learning algorithms.
Here every word in the corpus become a column in the DataFrame..
Converting it into a panda and also giving the option within the column option.
Here we convert the matrix into an array. Converting it into a panda data frame and also giving the name get_feature_names within the column option.
Let’s run it. It looks something like this:

It gives the count frequency of each word across different documents.
Sometimes we may get more insights about the data account of grouping two words together for example ‘beautiful place’ and ‘bad company’ has more meaning then just the individual words beautiful and please and Bad and company. We can get this information by doing what is called as the bigram. In the context of NLP or neurolinguistic programming a word is also called as a gram. Two words together it’s called bigram. The only change we did here was that in the Count_vectoriser function We added another option ngram_range. We can specify the range of words that we want to choose in the Count Vector representation. For example if you choose a range (1,2) we will get a frequency matrix of words as a single word or a unigram.
Gram which is two words appearing together in a given document year when we specify range (2,2) it will only give us frequency of words occurring in pairs.
Let’s run it and look at the output again.
Again the matrix is being converted into a data-frame just for the reference. so here we see features appearing as bigrams or two words appearing together and the count of them. Here we have, sentence 1 in each document sentence one only in the first document sentence three in the third document
Data can be classified into three types:
- Structured Datatype: Fits into relational database Management System where the data is perfectly aligned into rows or columns. A tabular format is used for representing data. Example: Data stored in MySQL data systems.
- Unstructured Datatype: Text file, pdf file, web server logs or WhatsApp messages with text, photos and voice attached to it. There’s no definite structure assigned to this data. It can be plain text, numbers or a sequence of bytes. It cannot be fit into rows or columns.
- Semi structured data: It is between structured and unstructured data. Example: XML file where unstructured data or text are embedded within tags to enforce some structure.


Stemming and lemmatisation helps to know the base word.
Stemming:

- Advantage: Faster algorithm
- Disadvantage: no exact base word, needs manual input
Lemmatisation: Tries to refer the dictionary and get the base word.

- Advantage:Manual intervention is very less.
- Disadvantage: Every word it refers the dictionary therefore it takes time.
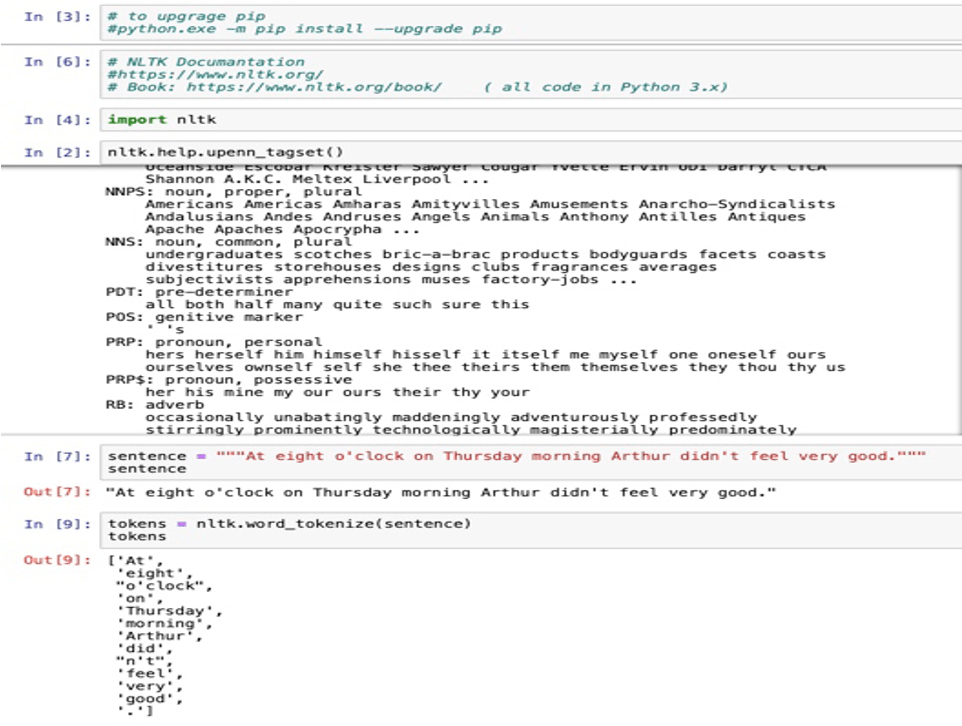
Token: Unit of characters, sentence or words.
NLP: Speech to Text.
Term frequencies how often a word appears in a document, divided by how many words are there. TF(t)= (Number of times T appears in a document/total number of terms in the document)
